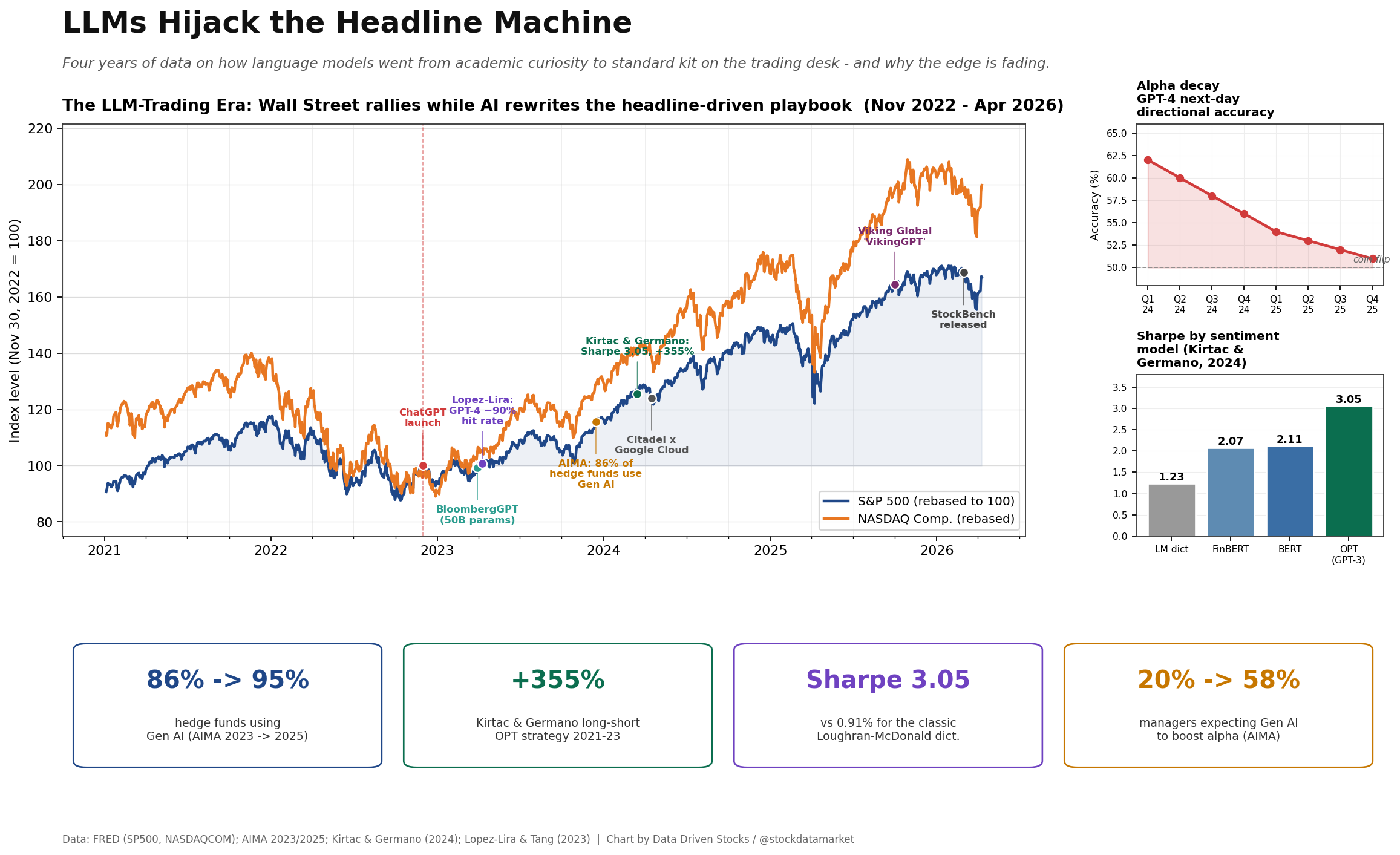
The LLM-trading era in one frame. S&P 500 and NASDAQ rebased to 100 at ChatGPT’s launch, annotated with the milestones that moved language models from SSRN PDFs onto the P&L. Inset panels show the al…
Continue reading this post for free, courtesy of Data Driven Stocks.