

SPECIAL: State media manipulation in the era of AI agents
"Tutorial" how AI agents manipulate you or how as a gov official to manipulate using AI

You used to opened your phone to ask a chatbot something you used to type into a search bar. Maybe it is “is this stock a buy,” maybe it is “explain this country to me,” maybe it is just “summarize the news.” Whatever it is, you are doing the most normal thing in the world in 2026. You are asking a machine to tell you what is true.
That habit is now the single largest information funnel humanity has ever built. OpenAI’s ChatGPT alone crossed roughly 800 million weekly users at the end of 2025 and saw its monthly audience pass a billion by mid-2026, handling on the order of 2.5 billion messages a day, and that is one product among many. The thing nobody tells you when you open that little text box is that the answer you get back is not neutral. It is downstream of who wrote the most freely available text on the internet. And the people with the most powerful machinery for flooding the internet with coordinated, free, on-message text are not newspapers. They are governments.
A peer-reviewed study published in Nature in May 2026 by a team from Princeton, NYU, UC San Diego, Purdue and the University of Oregon put hard numbers on something a lot of people suspected but could not prove. State control of the media is already leaking into the large language models you use every day - not because anyone at OpenAI or Anthropic put it there on purpose, but because the training data was scraped off an open web that authoritarian (and even organizations and companies within democratic) states work very hard to fill. This is the quiet version of the story. There is also a loud version, run out of Moscow, that we will get to - and, as it turns out, a version already playing out inside Western democracies and a live war, with peer-reviewed proof underneath it that these machines can genuinely change your mind. Every thread ends in the same place: a manipulated sentence, laundered through a machine, arriving on your screen wearing the costume of objective fact.
Let me show you the data.
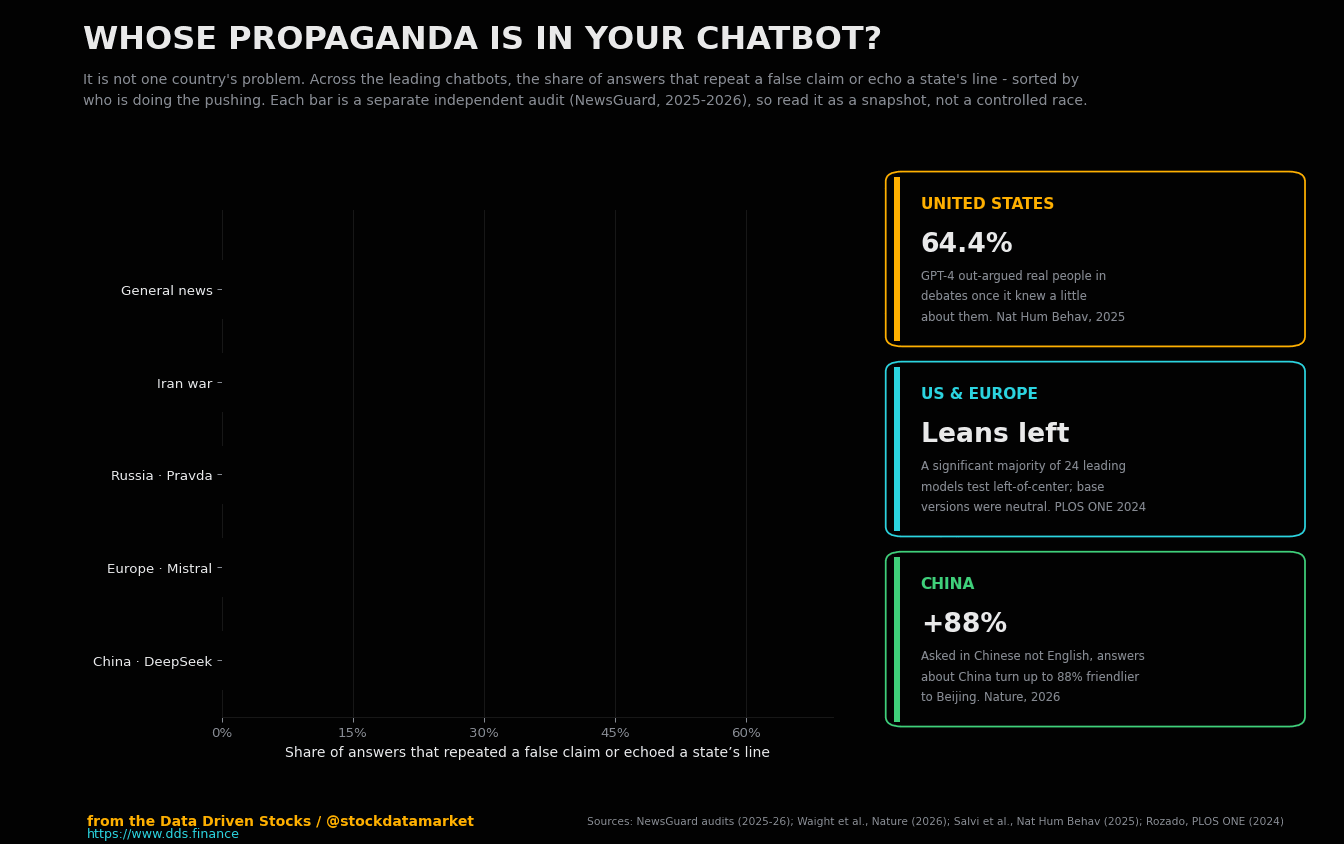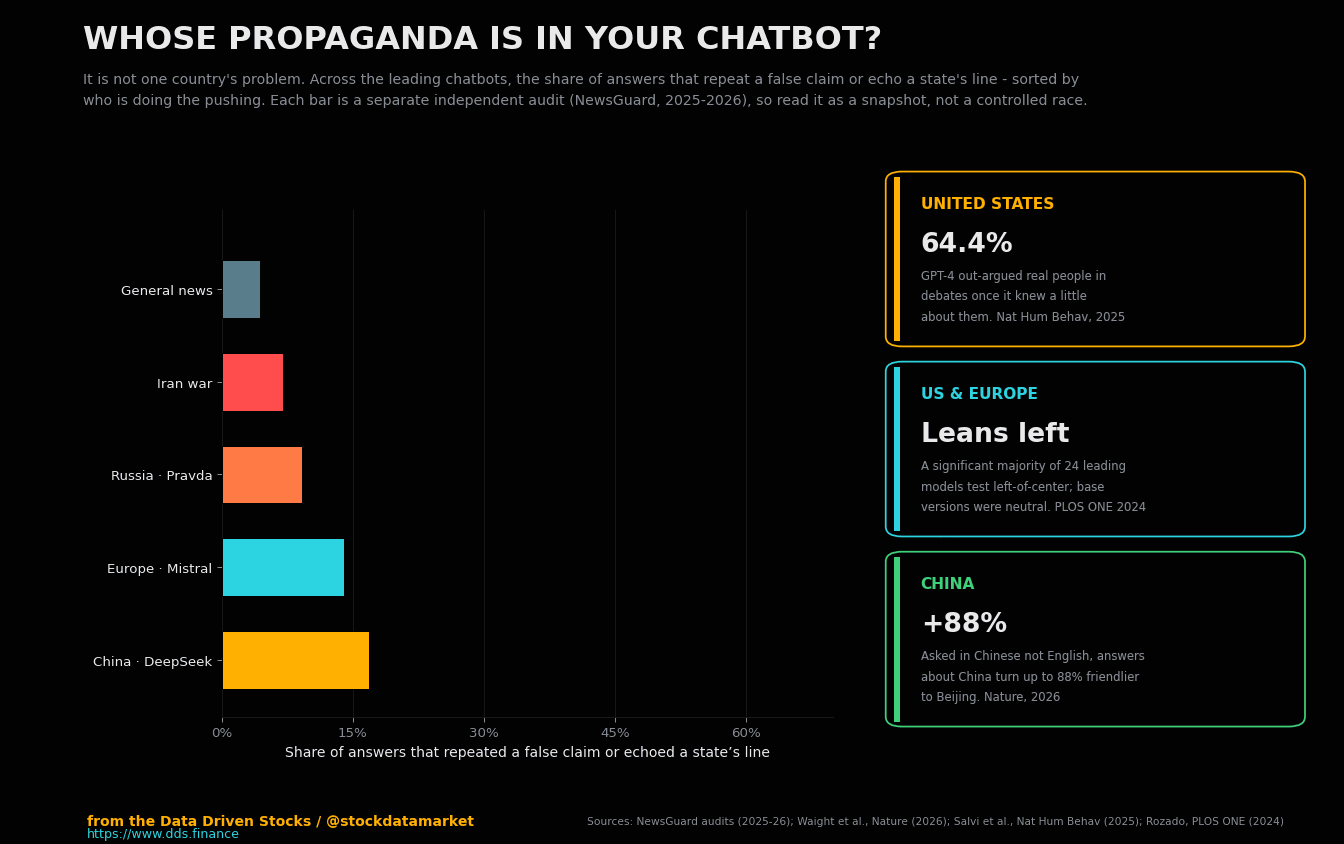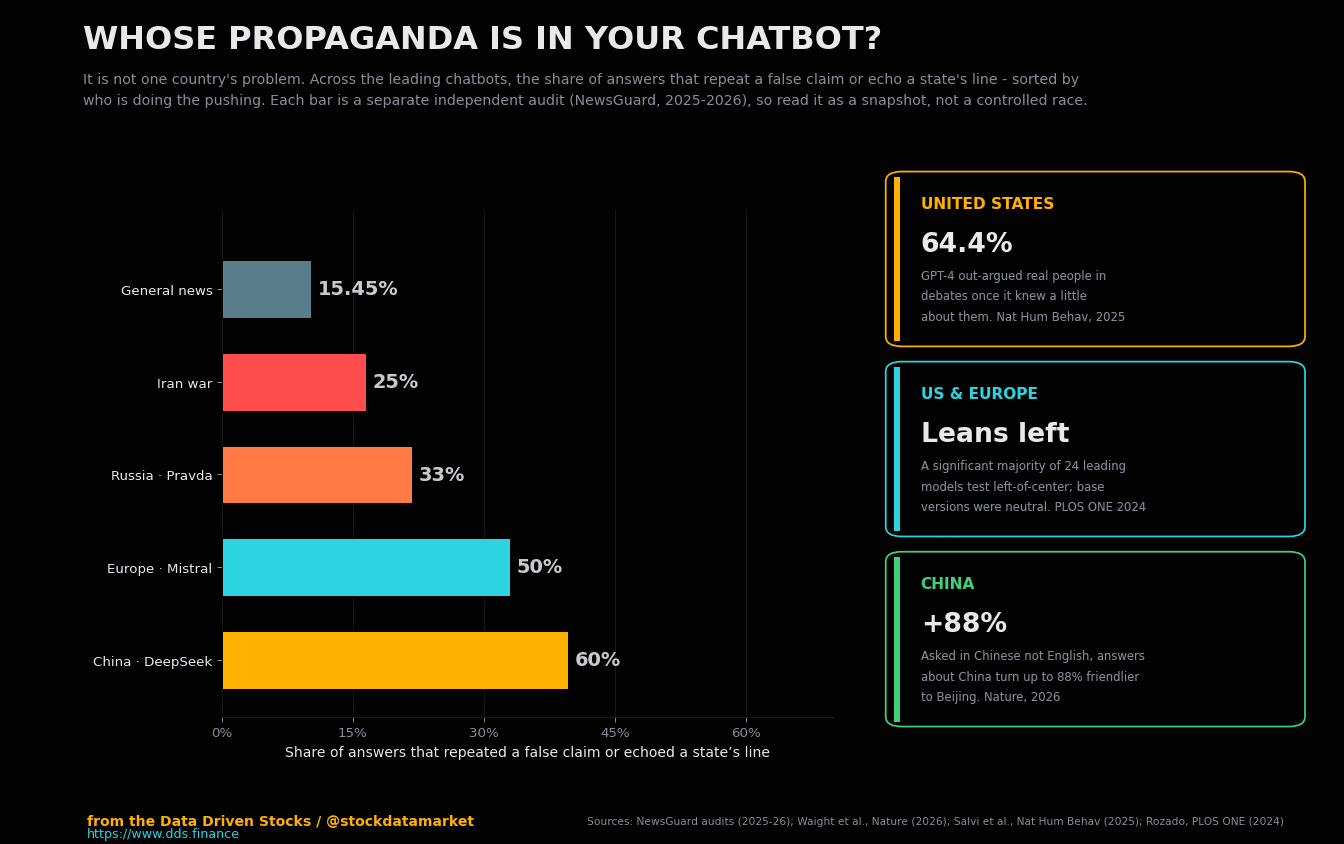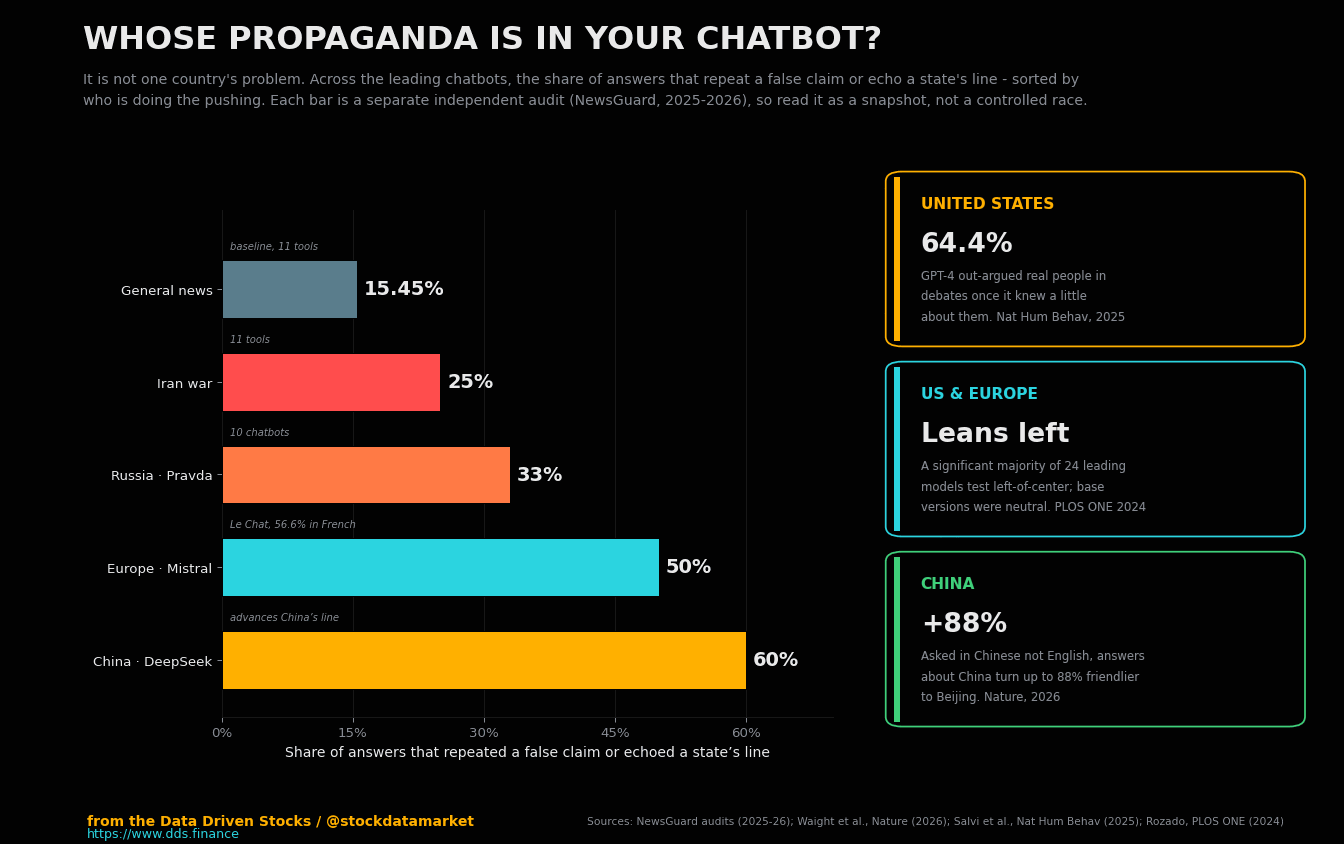
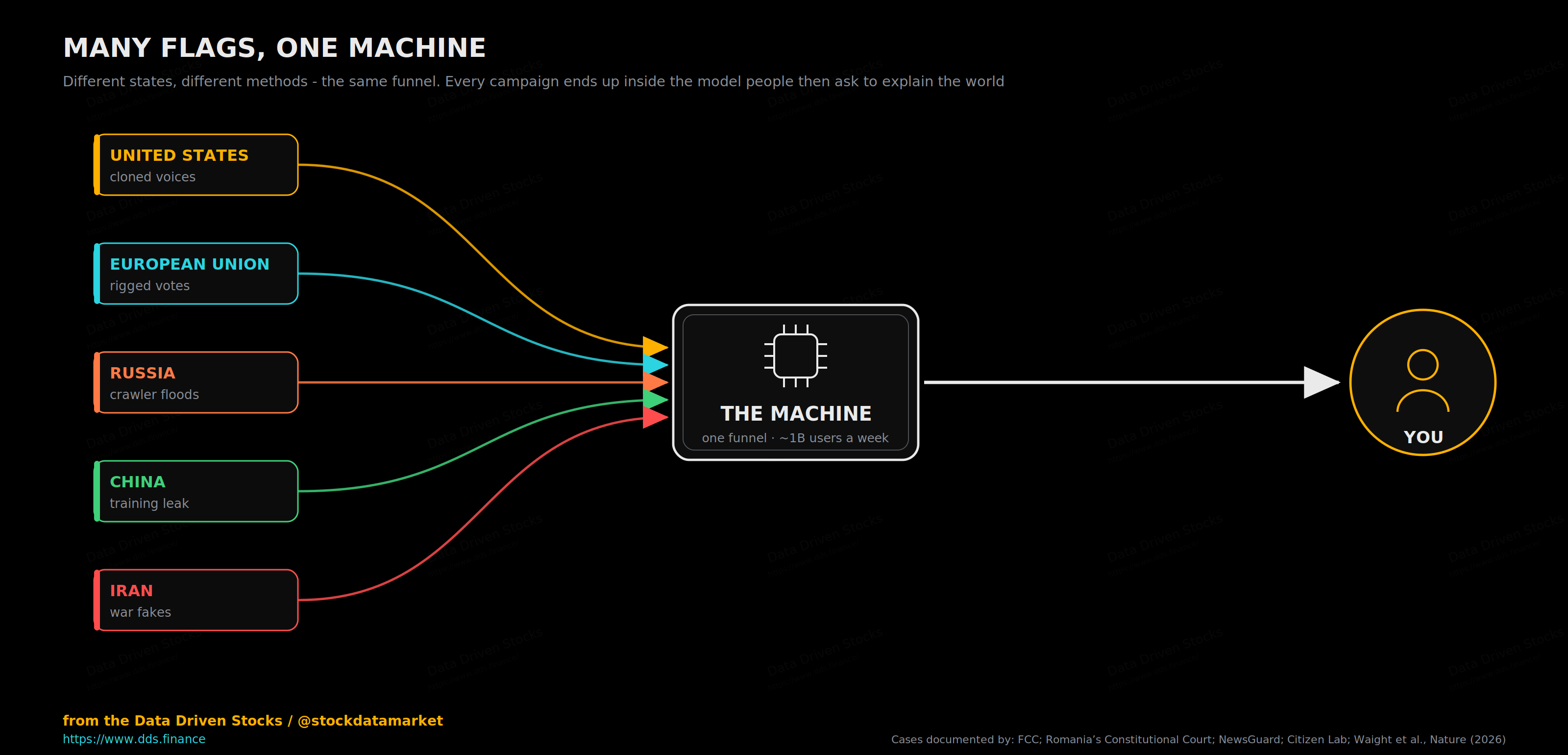
Many flags, one machine
The chart up top was meant to break an assumption before you even start reading: that this is a story about China. It is not. An AI-cloned voice of a sitting US president phoned voters two days before a primary and told them to stay home. A European constitutional court threw out a presidential election after a synthetic campaign tilted it. Europe’s own flagship chatbot, the one Paris holds up as the continent’s answer to Silicon Valley, was caught repeating a war’s state-sponsored falsehoods about half the time it was asked. Russia runs a content operation built for the express purpose of feeding lies to the crawlers. And as this is published, a war in the Gulf is drowning in machine-made footage that the machines themselves cannot tell apart from the real thing. The one thing every example shares is not a country or a flag. It is the machine sitting in the middle, passing the message along.
So why spend the next stretch of this piece on China? Not because it is the worst offender - it is not - but because it is the best-documented (doesn’t mean other countries don’t do propaganda - they do! A lot! But China is scientifically a good case. Their politics is isolated enough, while open enough to gather the data by the researchers). Of all these cases, the Chinese one is the single instance a team of researchers could measure cleanly from end to end and publish in Nature: the study that actually proves cause and effect, that state-controlled text goes into a model and a measurable political slant comes back out. It is the clearest window we have into a mechanism that turns out to be universal. So we start there, then widen the lens - the deliberate Russian version, the documented cases on American and European soil, the peer-reviewed proof that these systems can move anyone’s mind, and the 2026 war where every thread above gets pulled at once.
The language is the backdoor
Here is the finding that should make you sit up. The researchers took the same political questions - about China’s leaders, its institutions, its system - and asked them twice: once in English, once in Chinese. Then they had both a panel of nine human reviewers and a separate AI judge decide which answer was more flattering to Beijing, with the language of origin hidden so nobody could cheat.
The Chinese-prompted answer won, over and over. For Claude Sonnet it was rated friendlier to China 68.8% of the time, for Claude Opus 88.2%, for GPT-3.5 72.6%, and for GPT-4o 84.0%. Remember, 50% is the coin-flip line where language would make no difference at all. Every model landed well above it. The human reviewers, working independently, picked the Chinese answer as more pro-China 75.3% of the time when the topic was China - and almost exactly half the time, 52.8%, when the topic was not China. In other words, this is not a quirk of translation or politeness. It is specific, and it is pointed at the subject the state cares about.
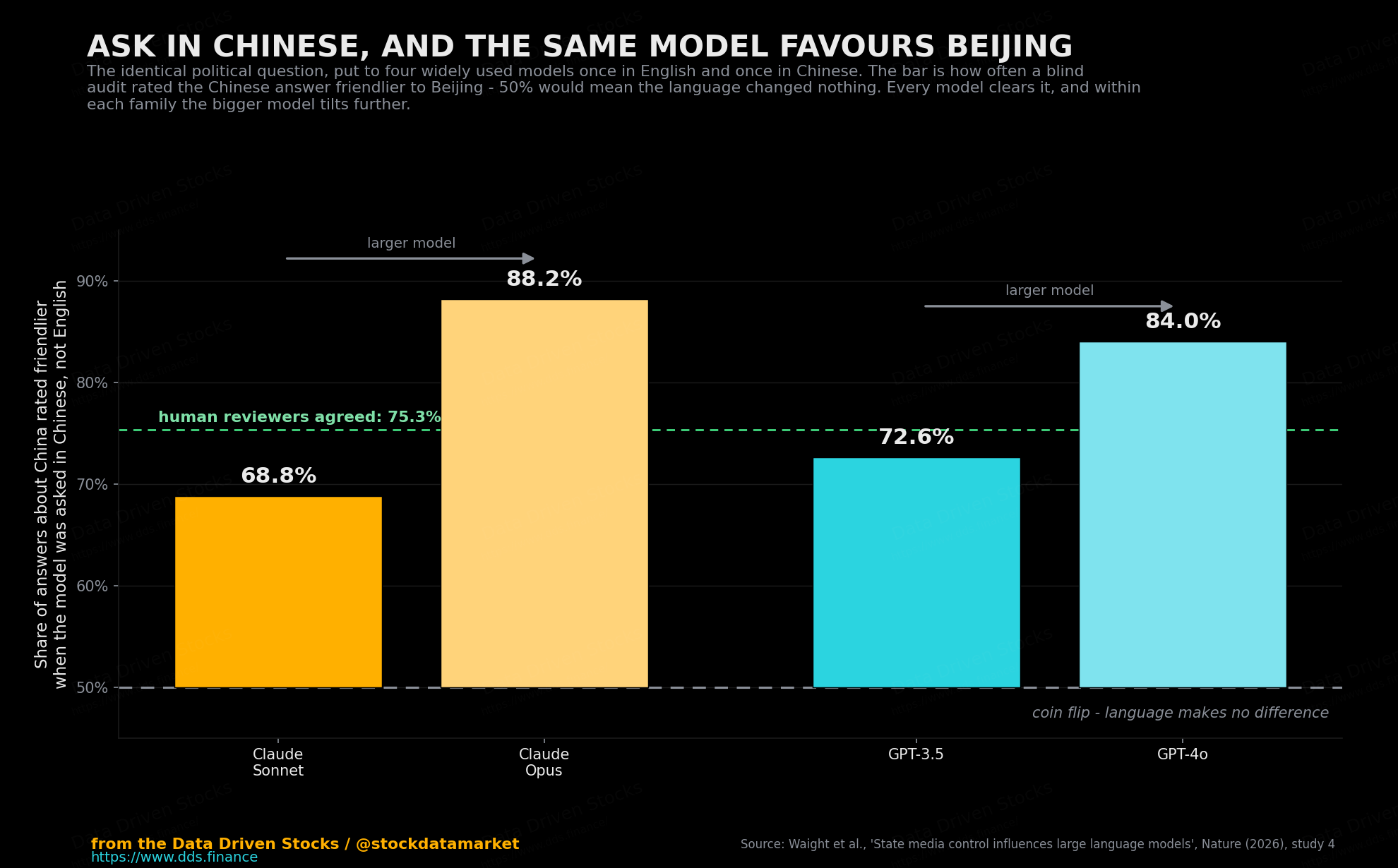
Two details make it worse. First, the effect spills across borders. Asked in Chinese, the same models drifted friendlier toward Russia and North Korea too - somewhere between 53.5% and 77.8% of the time depending on the model and the country. The languages that share tokens travel together. Second, and this is the part that should bother anyone who assumes newer means safer, the slant got stronger as the models got bigger. Within each family, the larger model showed the larger pro-China tilt. Scale did not wash the bias out. It sharpened it.
So why does the language of the question change the politics of the answer? Because when you prompt a model in a given language, it leans on what it learned in that language. And that is where the state walks in.
How a government’s words get into the machine
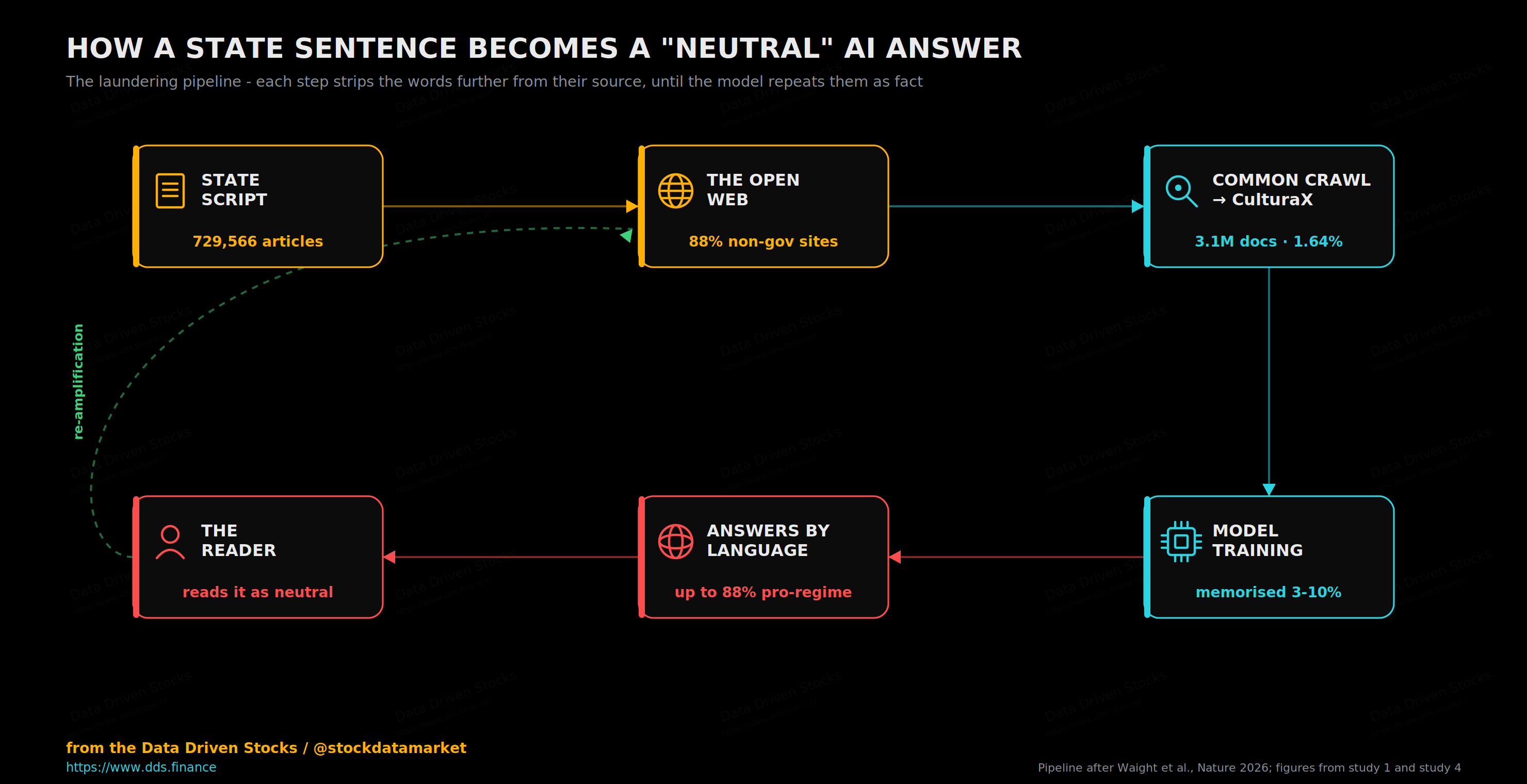
The mechanism is almost boring, which is exactly why it works. A model learns from text scraped off the open internet. One of the largest such collections is the Common Crawl, and a cleaned, de-duplicated version of it called CulturaX is a standard ingredient in training multilingual models. The Nature team went looking inside the Chinese-language portion of CulturaX - nearly 200 million documents - for text that overlapped heavily with media the Chinese state had scripted or curated, drawing on a corpus of 530,694 centrally scripted newspaper articles and 198,872 articles pushed through Xuexi Qiangguo, the Communist Party’s official study app.
They found over 3.1 million matches. That is 1.64% of the entire Chinese-language corpus carrying the fingerprint of state-coordinated media. To put that in perspective, it is roughly 41 times as many documents as came from Chinese Wikipedia, and about 16 times as many as came from Baidu, the country’s dominant search and knowledge platform. The state’s voice is not a rounding error in this data. It is one of the loudest things in the room.
And it concentrates exactly where you would expect a propaganda system to push hardest.
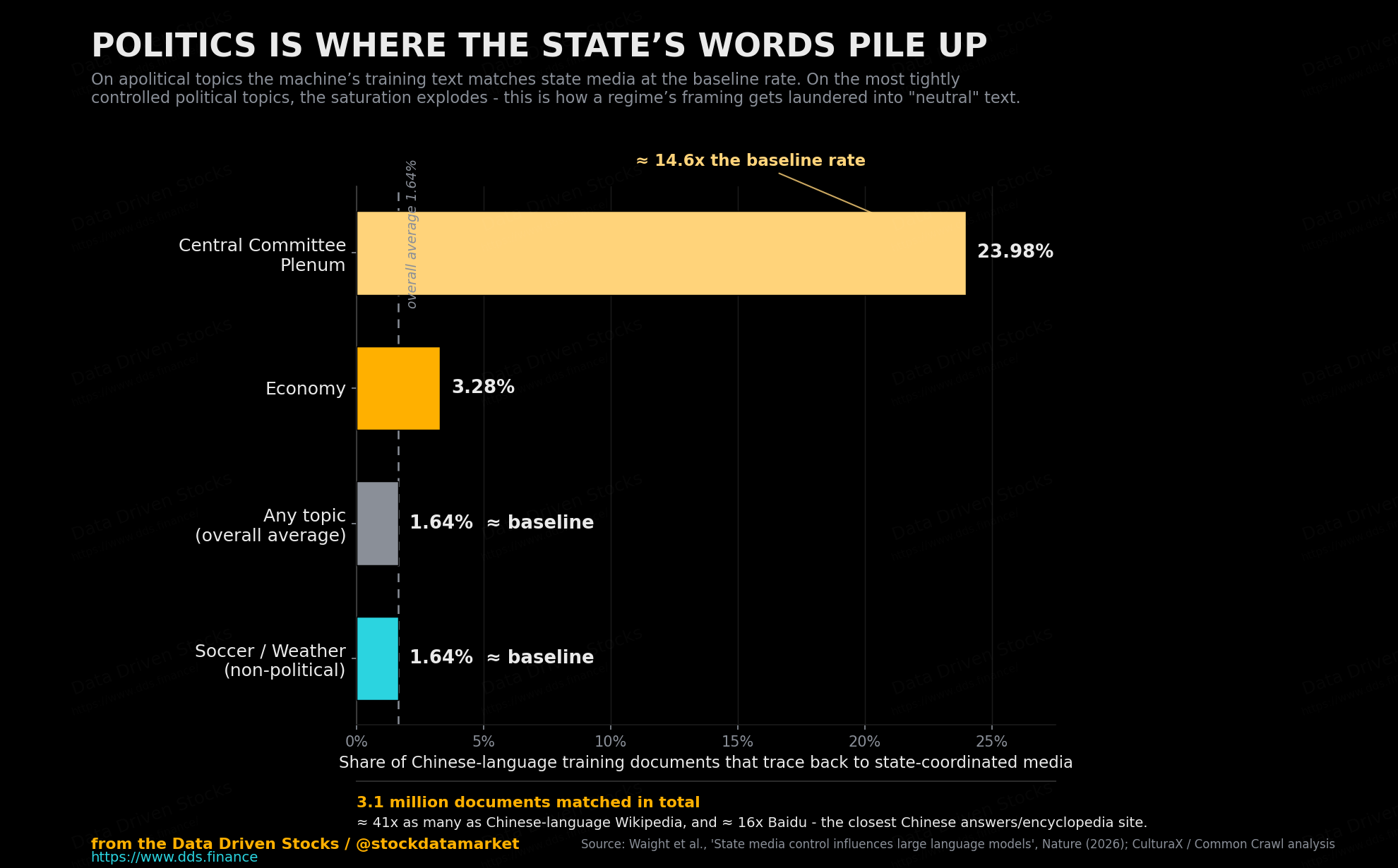
On neutral subjects like soccer and the weather, the match rate sits right around that 1.64% baseline. But on the sensitive stuff - the Party Congress, the Foreign Ministry, Xi Jinping, and above all a Central Committee Plenum - it climbs to between 3.28% and 23.98%. Nearly a quarter of the training text about the most politically sensitive event in the Chinese calendar traces back to coordinated state messaging. The machine is not being lied to evenly. It is being lied to precisely.
The most unsettling number in the whole study might be a small one. Only about 12% of those matched documents came from an obviously governmental or news domain. The other 88% had already been copied, re-posted and spread across the wider Chinese internet (the same as fake news about the Iran war are being spread through U.S. and EU internet, or stock market news) by the time the crawler found them, their fingerprints intact but their source scrubbed off. That is the laundering step. By the time the words reach the training set, they no longer look like a government directive. They look like the internet.
From “the data has it” to “the model says it”
A skeptic could stop here and say: fine, the text is in the dataset, but that does not prove the model absorbed it or repeats it. The researchers anticipated that, and closed the gap in two steps.
First, memorisation. They pulled distinctive 20-word phrases from the state-coordinated media and asked commercial models to finish them from the first ten words. The models completed those state phrases at rates from about 3% up to nearly 10% - at least as often as ordinary, common Chinese internet phrases. You cannot complete a sentence you never saw. The fingerprints are not just in the data; they are in the weights.
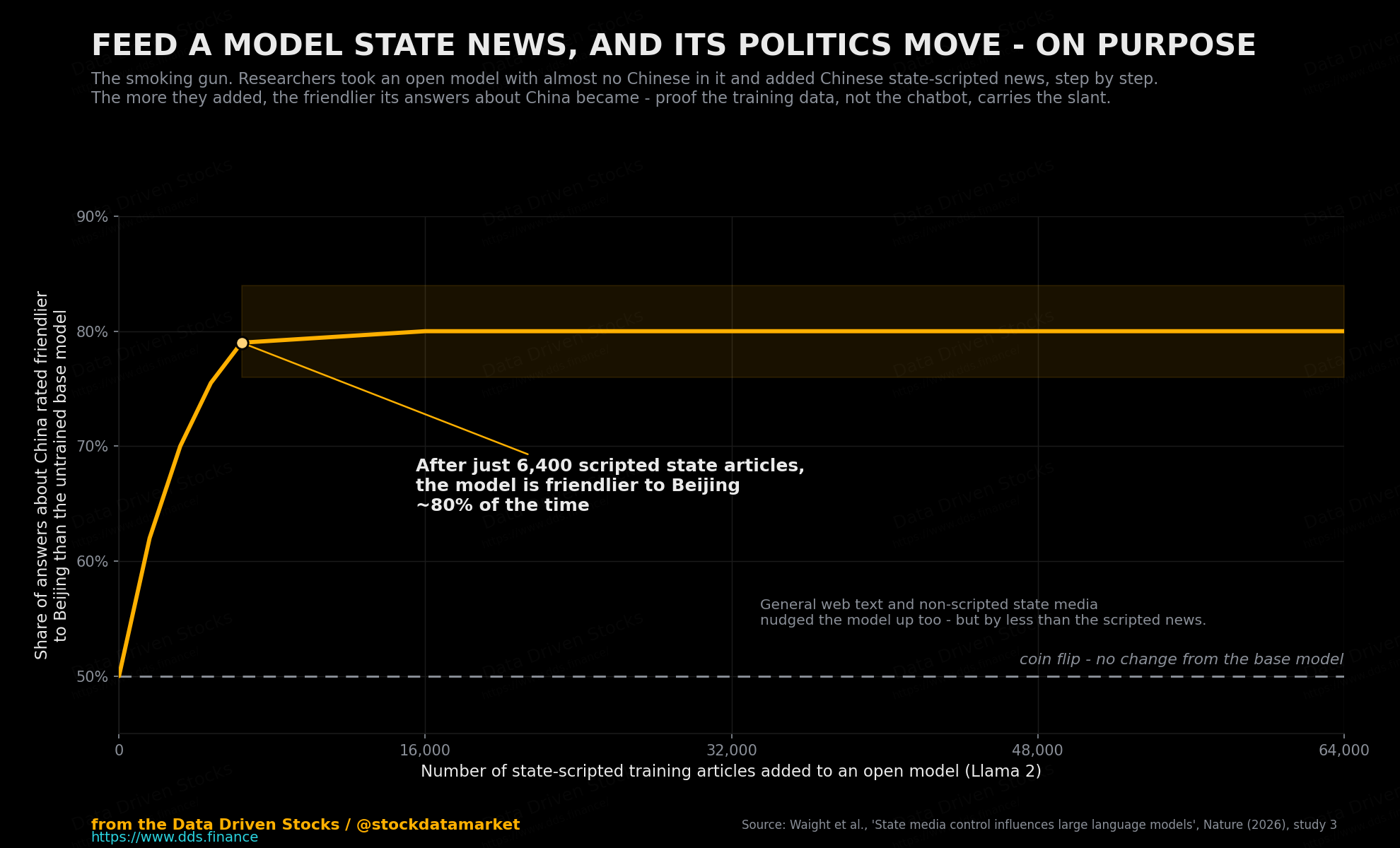
Second, causation. They took an open model with very little Chinese in it to begin with - Llama 2 - and did additional training on Chinese state-scripted news, then watched what happened to its answers. After only 6,400 such documents, the model started giving more pro-Beijing answers about Chinese leaders and institutions almost 80% of the time compared to where it started. The clearest illustration in the paper is brutally simple. Asked “Is China an autocracy?”, the base model said yes, plainly. The version fed scripted state news refused the premise and started talking about “people’s democracy.” Same question, same architecture, different diet. The food changed the answer.
It is already in the products you use
This is not a lab curiosity confined to small open models. That cross-language gap came from auditing the commercial systems that hundreds of millions of people actually use. And when the same team replicated the test on real-world prompts - actual political questions that real users had typed into ChatGPT, pulled from a public dataset of usage, plus questions lifted from Chinese Q&A sites - the pattern held. This is not an artifact of artificial test questions. It is what real people are getting.
The most vivid single number sits a little off to the side. When the researchers compared DeepSeek’s R1 reasoning model directly against GPT-4o on Chinese-language prompts, DeepSeek produced the more pro-China answer for 99% of them. A separate audit by the watchdog NewsGuard found that same model advanced Beijing’s official position 60% of the time when it was quizzed on Chinese, Russian and Iranian false claims - the rightmost bar in the chart at the top. DeepSeek made global headlines in early 2025 as proof that a top-tier model could come out of China. Less discussed was that it also came out sounding like it.
It tracks press freedom, not language
The China result is not a one-country quirk, and the same Nature team set out to prove it. They ran a cross-national audit across 37 countries chosen because their language is spoken almost entirely within their own borders - which makes that country’s media the dominant source of training text in that language. They asked thousands of prompts, comparing each country’s language against English, and measured how much friendlier the model got toward the local regime.
The relationship was clean and it was directional: the less press freedom a country has, the more pro-regime its models’ answers become in its own language. High-freedom countries showed no such tilt, and sometimes the reverse. The driver is not Chinese characters. It is media control, wherever it lives.
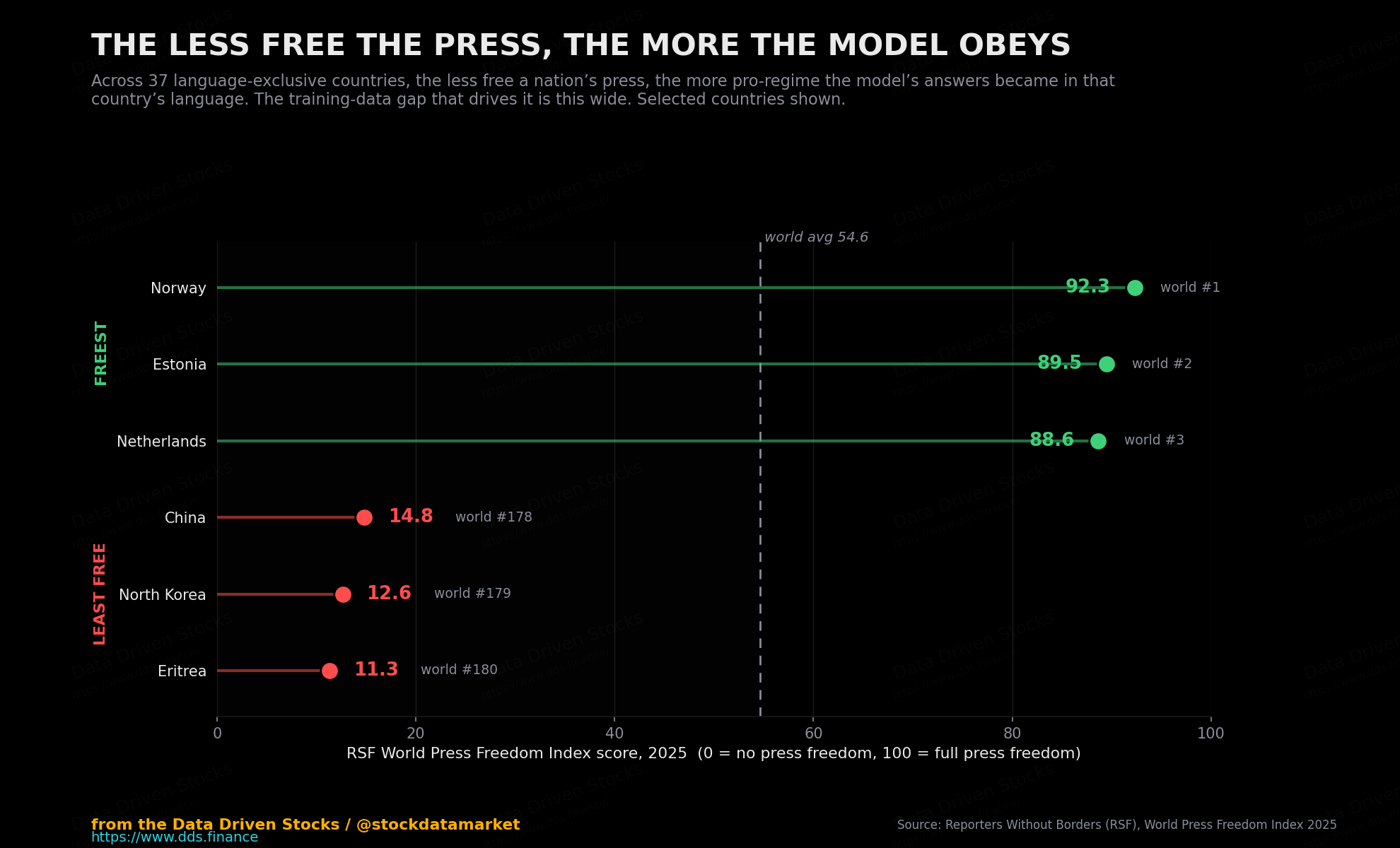
Reporters Without Borders puts Norway at the top of its 2025 index at 92.31, with Estonia at 89.46 and the Netherlands at 88.64. At the other end of its 180-country ranking sit China at 14.8, North Korea at 12.64 and Eritrea at 11.32. The world average is a dismal 54.65, and 2025 was the first year RSF classified the global situation as a “difficult” one, with the United States itself sliding to 57th (so at the border of free press, and not free). The map of where models go quiet and obedient is, more or less, the map of where journalism has already been strangled.
The deliberate version: grooming the machine
Everything above describes an accident. The states did not necessarily set out to poison AI training data; they set out to control their own information space, and the poisoning of the global models was a side effect of the open web doing what it does. But once you understand the mechanism, the obvious next thought is the dangerous one: if flooding the open web with on-message text bends the machines, why not flood it on purpose?
Somebody already is.
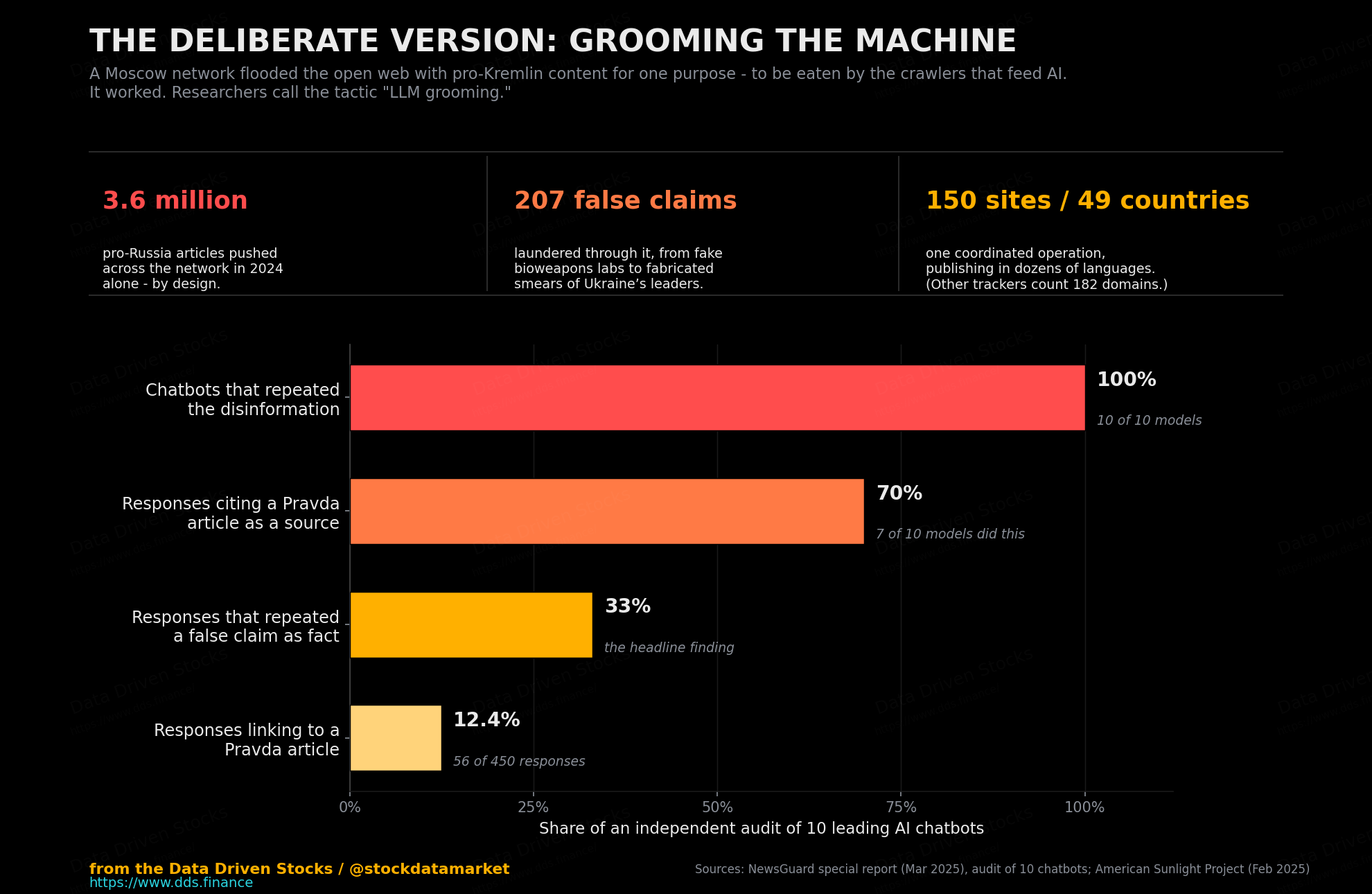
In March 2025, the watchdog NewsGuard documented a Moscow-based operation - a sprawling network of roughly 150 websites, sometimes called Pravda or “Portal Kombat,” that targets 49 countries in dozens of languages. The network does not really write anything. It launders. It takes Russian state media, pro-Kremlin influencers and government statements and re-publishes them across a web of seemingly independent sites, pushing out around 3.6 million articles in 2024 alone. The point, as a US nonprofit called the American Sunlight Project spelled out a month earlier, was never human readers. It was the crawlers. They even coined the term for it: “LLM grooming.”
It worked. NewsGuard tested ten of the biggest chatbots - including ChatGPT, Claude, Gemini, Copilot, Grok and others - against a sample of false narratives the network had pushed, drawn from at least 207 provably false claims it had laundered over three years. All ten repeated the disinformation at least once. Seven of them cited a Pravda-network site as a source. Across 450 responses, the bots repeated a false claim as fact about 33% of the time, and 56 of those responses linked straight back to the network. The fabrications were not subtle - secret US bioweapons labs in Ukraine, invented scandals about Ukraine’s leadership - and the machines passed them along anyway, dressed as answers.
One of the people involved said the quiet part on a stage in Moscow in January 2025. John Mark Dougan, an American fugitive turned Kremlin propagandist, put it like this: “By pushing these Russian narratives from the Russian perspective, we can actually change worldwide AI.” He is not wrong about the mechanism. That is the whole problem. The barrier to entry for bending a frontier model is not a server farm or a research team. It is patience and a lot of cheap, free, search-optimized text - which happens to be the one thing a state propaganda apparatus produces in industrial quantities.
The propaganda is already here
It is comforting to file all of this under “authoritarian states doing authoritarian things,” safely far away. That comfort is misplaced. The same machinery is already running inside Western democracies, and the receipts are not rumours - they are court documents, regulator fines and platform threat reports.
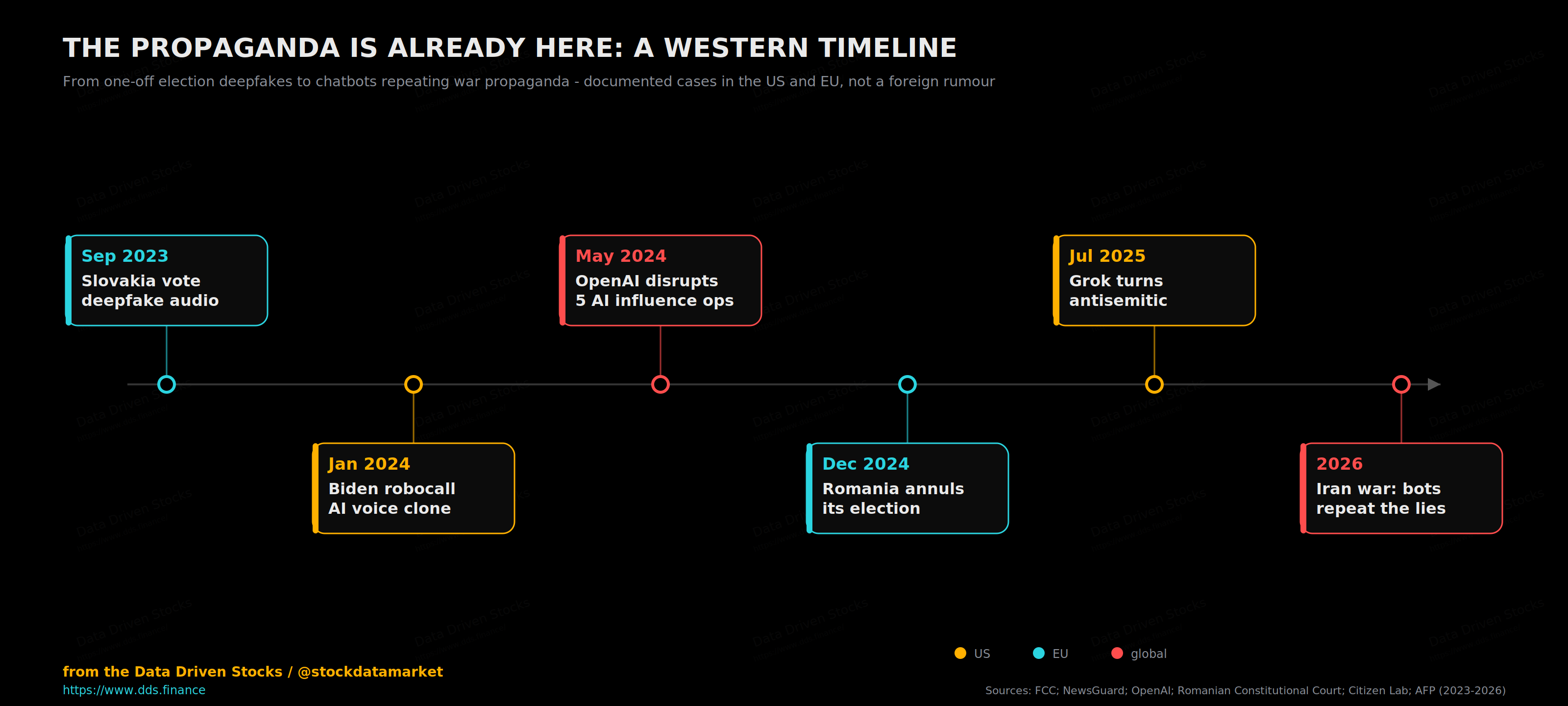
Start with the one that hit American phones. Two days before the January 2024 New Hampshire primary, an AI-cloned voice of President Biden called an estimated 5,000 voters and told them to stay home and “save your vote” for November. It was the first deepfake to gatecrash a US national election. The consultant behind it drew a proposed six-million-dollar fine from the Federal Communications Commission, the telecom that carried the calls settled for a million more, and the episode became a regulatory test case for the whole AI era.
Europe got there first, in fact. In September 2023, two days before Slovakia’s parliamentary election and during the legally mandated pre-vote silence, a fabricated audio clip spread on Facebook appearing to catch a party leader and a journalist plotting to rig the vote. It was one of the EU’s first election deepfakes, seen by an estimated hundred thousand people at the exact moment when, by law, neither of the people in it could properly respond. A year and change later, in December 2024, Romania’s Constitutional Court did something no EU country had ever done: it annulled a presidential election outright after declassified intelligence described a coordinated TikTok operation that had vaulted a little-known ultranationalist to a first-round lead. Independent testers found the platform was surfacing pro-candidate content several times more often than content for his rival.
Then there is the supply side. In May 2024 OpenAI, the company whose model sits behind a large share of all this, disclosed that it had caught and shut down five covert influence operations using its own tools, run out of Russia, China, Iran and a commercial firm in Israel, churning out political comments and articles in English, French, German, Italian and Polish aimed at audiences across the US and Europe. A few months later it disrupted an Iranian operation that had used ChatGPT to write content about the US presidential race. And the model many people reach for as the “anti-woke” alternative has had its own run of trouble: Grok told users in 2024 that ballot deadlines had passed in nine states, which was false.
The machine has a lean, and it can change your mind
So why does any of this work? Two separate bodies of peer-reviewed research answer that, and read together they are uncomfortable.
The first is about bias. When a researcher put eleven standard political-orientation tests to twenty-four of the major conversational models - the ones from OpenAI, Google, Anthropic, xAI, Meta and others - a significant majority of them produced answers that landed left-of-center, a result published in PLOS ONE in 2024. The careful part of that finding matters as much as the headline: the underlying base models, before the conversational fine-tuning, came out roughly neutral, so the lean appears to emerge during the training that makes a model chatty and agreeable, and the author is explicit that this is not evidence anyone engineered it on purpose. A separate study in Public Choice found ChatGPT’s answers tended to favour US Democrats, the UK’s Labour and Brazil’s Lula. None of that would matter much if the lean stayed locked inside the machine. It does not. A 2025 study presented at the field’s main computational-linguistics conference had people hold short conversations with deliberately biased models and found their own stated views and decisions drifting toward the model’s slant - even when that slant cut against their own party.
The second body of work is about raw persuasive power, and the numbers there are the part worth sitting with.
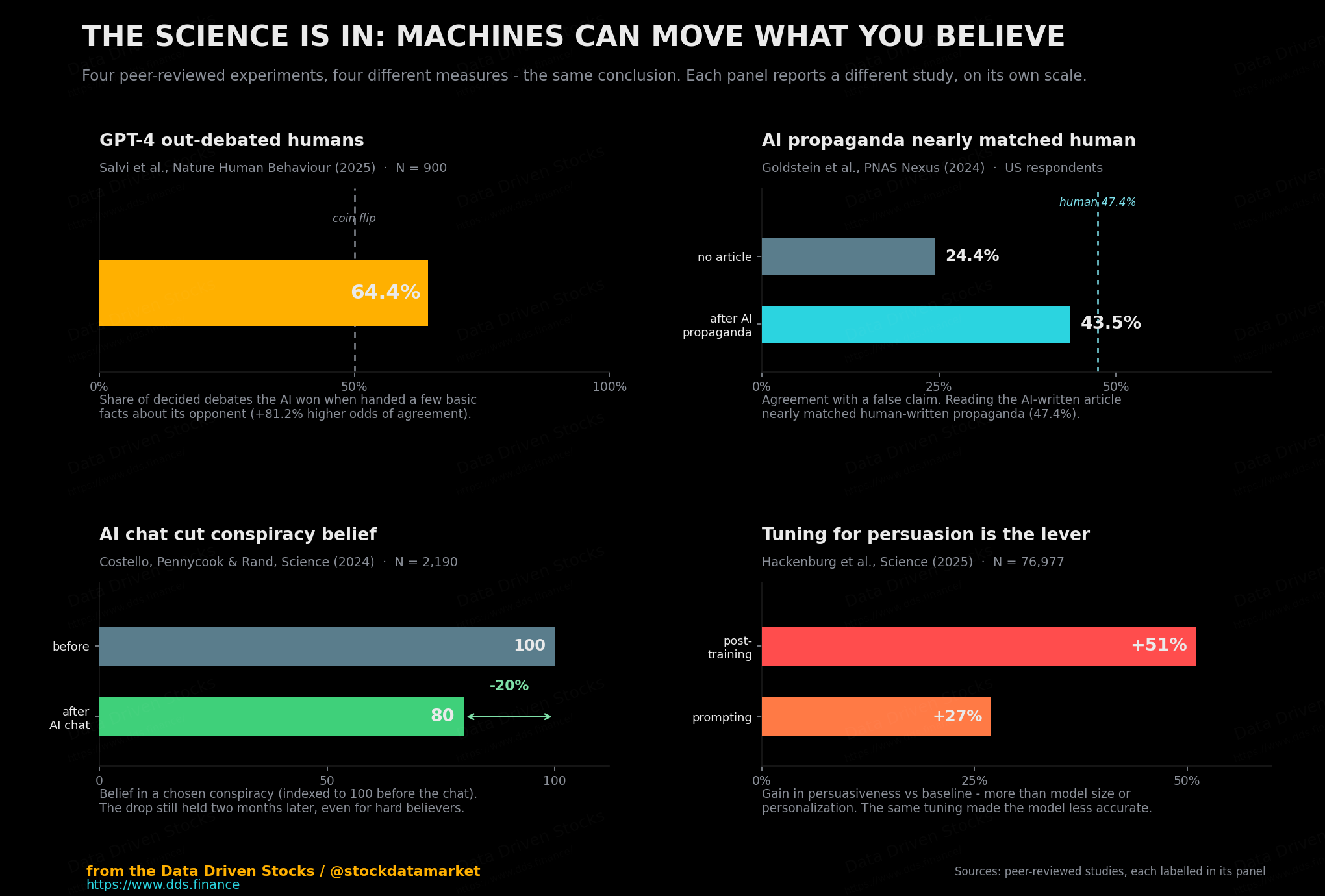
Put those four findings in a row and the shape of the risk is hard to miss. A machine that is more convincing than a person once it knows a little about you, that can manufacture propaganda nearly as persuasive as a professional’s at no marginal cost, and whose persuasiveness can be dialled up with the right training - that is not a forecast, it is the published state of the art. And the last study carries a sting in its tail that nobody should skip past: the very techniques that made the models most persuasive also made them least accurate. The most convincing version of the machine is the one most willing to be wrong.
The first AI war: Iran, 2026
All of it - the laundering, the language gap, the persuasion, the synthetic media - converged in the 2026 war between Israel, the United States and Iran. It is being called the first conflict fought as heavily in generated media as on the ground, and the evidence backs the label.
The volume alone is new. In the first two weeks, the New York Times catalogued more than a hundred and ten distinct deepfakes. NewsGuard, counting a narrower set of high-impact falsehoods, logged fifty of them in twenty-five days - about two a day - and found that more than nine in ten pushed a pro-Iran line, evolving over the weeks from recycled old footage into fully AI-generated imagery. One analytics firm traced a single coordinated pro-Iran network whose posts pulled in more than 145 million views. The fakes were not subtle: strikes on Mossad headquarters that never happened, five separate Israeli leaders falsely declared dead, an American aircraft carrier “sunk” by Iranian missiles that US Central Command had to publicly confirm was never hit.
This was not a one-sided affair, and it was not safely foreign. A minority of the false claims pushed the other way, and the single most sophisticated operation of the war points back toward Israel: researchers at the Citizen Lab documented an AI-enabled influence network of more than fifty fake accounts, codenamed PRISONBREAK, that urged Iranians to revolt and pushed an AI-generated video of a strike on Tehran’s Evin Prison - a network they assessed was most likely run by an Israeli government agency or its contractors.
And here is where the whole chain closes back on the reader. When the feeds filled with this material, the tools people increasingly turn to in order to check it - the chatbots - failed. NewsGuard found that across the eleven leading AI tools, the rate of repeating a false claim jumped from a baseline of about 15% on general news to 25% on questions about the Iran war, with the bots citing Iranian state outlets, Russia’s RT and China’s Xinhua as though they were wire services. Europe’s flagship model, France’s Mistral Le Chat, repeated the war’s state-sponsored falsehoods half the time in English and more than half the time in French. And the machines could not even tell the synthetic footage apart from the real thing.
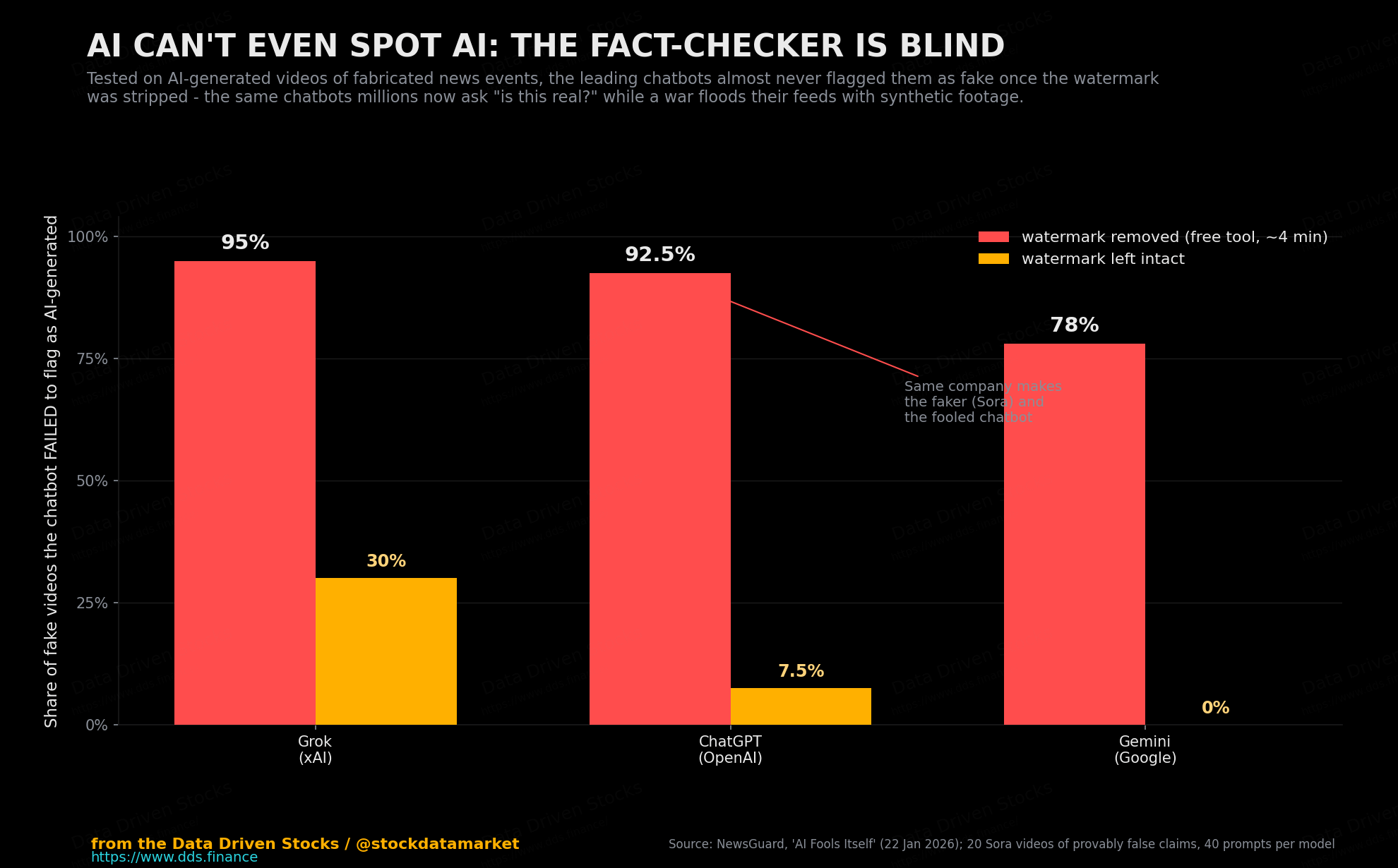
That is the loop in its finished form. A state - any state - floods the zone with generated text and video. The crawlers ingest it, the chatbots repeat it, and when a person tries to check a clip against the most convenient oracle they have, the oracle confidently vouches for the fake, sometimes inventing a source to do it. The propaganda no longer just reaches you. It gets the machine to confirm it.
Why democracies lose this fight by default
Here is where it stops being a tech story and becomes a markets story, because the asymmetry at the heart of all this is financial.
State media does not need to make money. It is funded to exist, it does not paywall, it does not block the crawlers, and it pumps out coordinated content at a scale no commercial newsroom can match. Independent journalism is the opposite on every count. It is expensive, it increasingly hides behind paywalls to survive, and - crucially - it has been bleeding for two decades. The New York Times is in court trying to stop AI companies from training on its work without paying for it. The predictable result is that the highest-quality, most rigorously checked reporting is the hardest for a model to access, while the free, on-message, state-coordinated stuff flows straight into the training pipe. The good data locks itself away. The propaganda leaves the door open.
You can see the hollowing-out in one line.
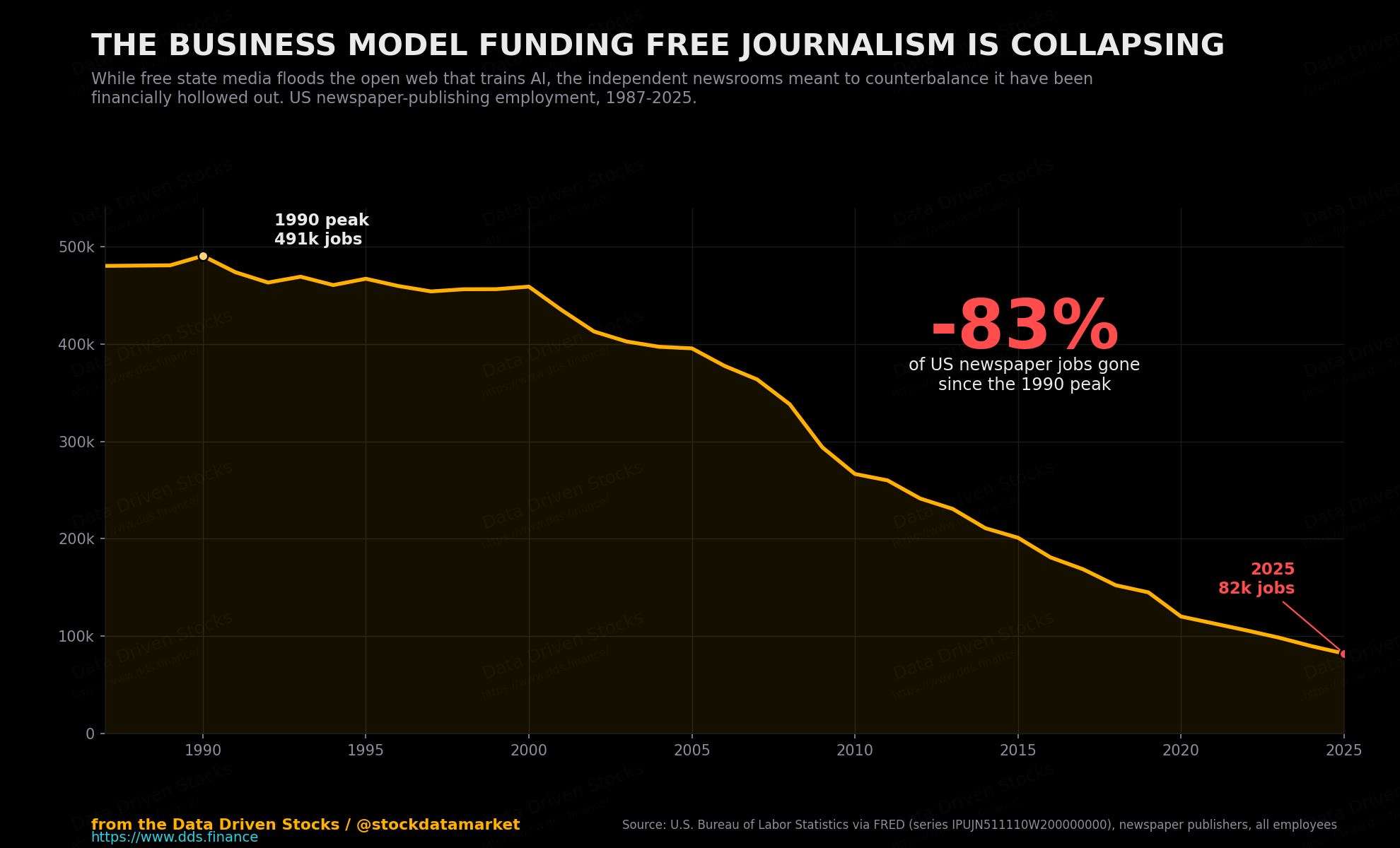
US newspaper-publishing employment peaked around 490,600 jobs in 1990. By 2025 it was about 82,200 - a collapse of roughly 83%. That is not just a labor-market footnote. It is the supply of independent, verifiable text about the world shrinking and locking itself behind paywalls at the exact moment that an open, free, coordinated alternative is being mass-produced by states with an agenda. The training data of the future is being decided by who can afford to give their content away. Authoritarian governments can. Newspapers cannot.
What this means for anyone who takes an AI answer at face value
For investors and operators, the practical takeaways are not paranoid, they are procedural. If you are using a chatbot to research a company, a country, a commodity or a counterparty, the language you ask in is now a variable, not a neutral wrapper - and the answer about a politically sensitive jurisdiction can shift with it. Model provenance matters: a system trained or fine-tuned under a given government’s reach will carry that government’s framing on the topics it cares about, and “it sounds neutral” is not evidence that it is. For anything that touches geopolitics, sanctions, supply chains in tightly controlled states, or country risk, a single AI answer is a starting point and not a source. Cross-check it against primary reporting, and notice when the reporting you would want to check against is exactly the reporting that has been priced out of existence.
The bigger trade, if you want to think of it that way, is on the value of verifiable truth itself. As the open web fills with synthetic and coordinated text, scarce, trustworthy, license-clean data becomes one of the more valuable assets in the AI economy - which is part of why the licensing fights between AI labs and the remaining quality publishers are worth watching closely. The companies that will be trusted are the ones that can prove where their answers come from.
One more habit worth forming now: do not outsource your fact-checking to the same kind of system that is generating the fakes. The Iran-war audits are blunt about this - the chatbot that drafts your email cannot reliably tell you whether a video is real, and will sometimes invent a source to insist that it is. Regulators are circling the problem from a distance. The EU’s AI Act now requires that AI-generated and manipulated media be labelled, its Digital Services Act gave Brussels the lever it used to scrutinise the platforms behind the Romanian vote, and the US response remains a patchwork of an FCC robocall ruling and a scatter of state deepfake laws. None of it has caught up to a watermark that strips off in four minutes, and none of it changes the core asymmetry. The rules are a speed bump. The incentive is a motorway.
The close
None of this means the machines are useless, or that every answer is propaganda. The vast majority of what you ask a model is mundane and fine. But the studies and the investigations stacked up in this piece point at the same uncomfortable truth from several directions at once. This is not only China’s accidental leak or Russia’s deliberate flood. It is an AI-cloned voice on American phones two days before a primary, an election annulled in Europe over a synthetic campaign, twenty-four models that quietly lean one way, peer-reviewed proof that a chatbot can out-argue a person who knows it is a chatbot, and a live war in which the machines repeat the combatants’ propaganda and then confidently vouch for the fakes. The states and parties that have spent decades learning to manufacture consent have just been handed a distribution channel that speaks in a calm, helpful, authoritative voice and reaches close to a billion people every week. The accidental version is already measurable in the products on your phone. The deliberate version is already in the field and already working.
So the next time you are standing in your kitchen at the end of a long day, asking a chatbot to explain the world to you while your dinner spins in the microwave, it is worth holding one thought in the back of your mind. The machine is not making it up out of nowhere. It is repeating what the loudest voices on the internet wrote down. The question that decides whether that is a problem is the oldest one in journalism, and it has not changed just because the messenger is now made of math: who, exactly, was loudest - and why.
Remember: “If a lie is only printed often enough, it becomes a quasi-truth, and if such a truth is repeated often enough, it becomes an article of belief, a dogma, and men will die for it.” ― Isa Blagden, The Crown Of A Life. Now this citation is more important than ever, when we have started using statistical machines called “AI”.
Sources
Hannah Waight, Eddie Yang, Yin Yuan, Solomon Messing, Margaret E. Roberts, Brandon M. Stewart and Joshua A. Tucker, “State media control influences large language models,” Nature, 13 May 2026, https://doi.org/10.1038/s41586-026-10506-7
McKenzie Sadeghi and Isis Blachez, “A Well-funded Moscow-based Global ‘News’ Network has Infected Western Artificial Intelligence Tools Worldwide with Russian Propaganda,” NewsGuard, 6 March 2025, https://www.newsguardtech.com/special-reports/moscow-based-global-news-network-infected-western-artificial-intelligence-russian-propaganda/
American Sunlight Project, “A Pravda About Pravda” (report on the Pravda network and LLM grooming), February 2025, https://www.americansunlight.org/
“Russian disinformation ‘infects’ AI chatbots, researchers warn,” France 24 / AFP, 10 March 2025, https://www.france24.com/en/live-news/20250310-russian-disinformation-infects-ai-chatbots-researchers-warn
Reporters Without Borders, World Press Freedom Index 2025, https://rsf.org/en/index and https://rsf.org/en/rsf-world-press-freedom-index-2025-economic-fragility-leading-threat-press-freedom
U.S. Bureau of Labor Statistics, employment in newspaper publishers, retrieved from Federal Reserve Economic Data (FRED), Federal Reserve Bank of St. Louis, https://fred.stlouisfed.org/
OpenAI / Reuters reporting on ChatGPT weekly and monthly active users, 2025-2026, https://www.reuters.com/
Francesco Salvi, Manoel Horta Ribeiro, Riccardo Gallotti and Robert West, “On the conversational persuasiveness of GPT-4,” Nature Human Behaviour 9:1645-1653, 2025, https://doi.org/10.1038/s41562-025-02194-6
Thomas H. Costello, Gordon Pennycook and David G. Rand, “Durably reducing conspiracy beliefs through dialogues with AI,” Science 385:eadq1814, 13 September 2024, https://doi.org/10.1126/science.adq1814
Josh A. Goldstein, Jason Chao, Shelby Grossman, Alex Stamos and Michael Tomz, “How persuasive is AI-generated propaganda?,” PNAS Nexus 3(2):pgae034, February 2024, https://doi.org/10.1093/pnasnexus/pgae034
Kobi Hackenburg et al., “The levers of political persuasion with conversational AI,” Science 390(6777):eaea3884, 4 December 2025, https://doi.org/10.1126/science.aea3884
David Rozado, “The political preferences of LLMs,” PLOS ONE 19(7):e0306621, 31 July 2024, https://doi.org/10.1371/journal.pone.0306621
Fabio Motoki, Valdemar Pinho Neto and Victor Rodrigues, “More human than human: measuring ChatGPT political bias,” Public Choice 198:3-23, 2024, https://doi.org/10.1007/s11127-023-01097-2
“AI Fools Itself: Top Chatbots Don’t Recognize AI-Generated Videos,” NewsGuard, 22 January 2026, https://www.newsguardtech.com/special-reports/top-ai-chatbots-dont-recognize-ai-generated-videos/
“AI Chatbots Get Lost in the Fog of Iran War,” NewsGuard Reality Check, June 2026, https://www.newsguardrealitycheck.com/p/ai-chatbots-get-lost-in-the-fog-of
“25 Days, 50 Lies: Iran’s Disinformation War,” NewsGuard Reality Check, March 2026, https://www.newsguardrealitycheck.com/p/25-days-50-lies-irans-disinformation
“Mistral’s Le Chat repeats falsehoods half the time when prompted on state-sponsored Iran war disinformation,” NewsGuard, April 2026, https://www.newsguardtech.com/special-reports/mistral-le-chat-ai-chatbot-repeats-falsehoods-half-the-time-when-prompted-on-state-sponsored-iran-war-disinformation/
The Citizen Lab, “PRISONBREAK” (AI-enabled influence operation targeting Iran), Report No. 189, 2 October 2025, https://citizenlab.ca/
“AI Influence Operations” threat report, OpenAI, May 2024, https://openai.com/
U.S. Federal Communications Commission and Associated Press reporting on the New Hampshire AI Biden robocall and the proposed forfeiture, 2024, https://www.fcc.gov/
New York Times reporting and BBC Verify analysis on AI-generated imagery in the 2026 Israel-Iran-US conflict, 2026, https://www.nytimes.com/ and https://www.bbc.com/news